Redux Essentials, Part 8: RTK Query Advanced Patterns
- How to use tags with IDs to manage cache invalidation and refetching
- How to work with the RTK Query cache outside of React
- Techniques for manipulating response data
- Implementing optimistic updates and streaming updates
- Completion of Part 7 to understand RTK Query setup and basic usage
Introduction
In Part 7: RTK Query Basics, we saw how to set up and use the RTK Query API to handle data fetching and caching in our application. We added an "API slice" to our Redux store, defined "query" endpoints to fetch posts data, and a "mutation" endpoint to add a new post.
In this section, we'll continue migrating our example app to use RTK Query for the other data types, and see how to use some of its advanced features to simplify the codebase and improve user experience.
Some of the changes in this section aren't strictly necessary - they're included to demonstrate RTK Query's features and show some of the things you can do, so you can see how to use these features if you need them.
Editing Posts
We've already added a mutation endpoint to save new Post entries to the server, and used that in our <AddPostForm>. Next, we need to handle updating the <EditPostForm> to let us edit an existing post.
Updating the Edit Post Form
As with adding posts, the first step is to define a new mutation endpoint in our API slice. This will look much like the mutation for adding a post, but the endpoint needs to include the post ID in the URL and use an HTTP PATCH request to indicate that it's updating some of the fields.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
Once that's added, we can update the <EditPostForm>. It needs to read the original Post entry from the store, use that to initialize the component state to edit the fields, and then send the updated changes to the server. Currently, we're reading the Post entry with selectPostById, and manually dispatching a postUpdated thunk for the request.
We can use the same useGetPostQuery hook that we used in <SinglePostPage> to read the Post entry from the cache in the store, and we'll use the new useEditPostMutation hook to handle saving the changes. If desired, we can also add a spinner and disable the form inputs while the update is in progress as well.
import React from 'react'
import { useNavigate, useParams } from 'react-router-dom'
import { Spinner } from '@/components/Spinner'
import { useGetPostQuery, useEditPostMutation } from '@/features/api/apiSlice'
// omit form types
export const EditPostForm = () => {
const { postId } = useParams()
const navigate = useNavigate()
const { data: post } = useGetPostQuery(postId!)
const [updatePost, { isLoading }] = useEditPostMutation()
if (!post) {
return (
<section>
<h2>Post not found!</h2>
</section>
)
}
const onSavePostClicked = async (
e: React.FormEvent<EditPostFormElements>
) => {
// Prevent server submission
e.preventDefault()
const { elements } = e.currentTarget
const title = elements.postTitle.value
const content = elements.postContent.value
if (title && content) {
await updatePost({ id: post.id, title, content })
navigate(`/posts/${postId}`)
}
}
// omit rendering
}
Cache Data Subscription Lifetimes
Let's try this out and see what happens. Open up your browser's DevTools, go to the Network tab, refresh the page, clear the network tab, then login. You should see a GET request to /posts as we fetch the initial data. When you click on a "View Post" button, you should see a second request to /posts/:postId that returns that single post entry.
Now click "Edit Post" inside the single post page. The UI switches over to show <EditPostForm>, but this time there's no network request for the individual post. Why not?

RTK Query allows multiple components to subscribe to the same data, and will ensure that each unique set of data is only fetched once. Internally, RTK Query keeps a reference counter of active "subscriptions" to each endpoint + cache key combination. If Component A calls useGetPostQuery(42), that data will be fetched. If Component B then mounts and also calls useGetPostQuery(42), it's asking for the same data. We already have an existing cache entry, so there's no need for a request. The two hook usages will return the exact same results, including fetched data and loading status flags.
When the number of active subscriptions goes down to 0, RTK Query starts an internal timer. If the timer expires before any new subscriptions for the data are added, RTK Query will remove that data from the cache automatically, because the app no longer needs the data. However, if a new subscription is added before the timer expires, the timer is canceled, and the already-cached data is used without needing to refetch it.
In this case, our <SinglePostPage> mounted and requested that individual Post by ID. When we clicked on "Edit Post", the <SinglePostPage> component was unmounted by the router, and the active subscription was removed due to unmounting. RTK Query immediately started a "remove this post data" timer. But, the <EditPostPage> component mounted right away and subscribed to the same Post data with the same cache key. So, RTK Query canceled the timer and kept using the same cached data instead of fetching it from the server.
By default, unused data is removed from the cache after 60 seconds, but this can be configured in either the root API slice definition or overridden in the individual endpoint definitions using the keepUnusedDataFor flag, which specifies a cache lifetime in seconds.
Invalidating Specific Items
Our <EditPostForm> component can now save the edited post to the server, but we have a problem. If we click "Save Post" while editing, it returns us to the <SinglePostPage>, but it's still showing the old data without the edits. The <SinglePostPage> is still using the cached Post entry that was fetched earlier. For that matter, if we return to the main page and look at the <PostsList>, it's also showing the old data. We need a way to force a refetch of both the individual Post entry, and the entire list of posts.
Earlier, we saw how we can use "tags" to invalidate parts of our cached data. We declared that the getPosts query endpoint provides a 'Post' tag, and that the addNewPost mutation endpoint invalidates that same 'Post' tag. That way, every time we add a new post, we force RTK Query to refetch the entire list of posts from the getQuery endpoint.
We could add a 'Post' tag to both the getPost query and the editPost mutation, but that would force all the other individual posts to be refetched as well. Fortunately, RTK Query lets us define specific tags, which let us be more selective in invalidating data. These specific tags look like {type: 'Post', id: 123}.
Our getPosts query defines a providesTags field that is an array of strings. The providesTags field can also accept a callback function that receives the result and arg, and returns an array. This allows us to create tag entries based on IDs of data that is being fetched. Similarly, invalidatesTags can be a callback as well.
In order to get the right behavior, we need to set up each endpoint with the right tags:
getPosts: provides a general'Post'tag for the whole list, as well as a specific{type: 'Post', id}tag for each received post objectgetPost: provides a specific{type: 'Post', id}object for the individual post objectaddNewPost: invalidates the general'Post'tag, to refetch the whole listeditPost: invalidates the specific{type: 'Post', id}tag. This will force a refetch of both the individual post fromgetPost, as well as the entire list of posts fromgetPosts, because they both provide a tag that matches that{type, id}value.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query<Post[], void>({
query: () => '/posts',
providesTags: (result = [], error, arg) => [
'Post',
...result.map(({ id }) => ({ type: 'Post', id }) as const)
]
}),
getPost: builder.query<Post, string>({
query: postId => `/posts/${postId}`,
providesTags: (result, error, arg) => [{ type: 'Post', id: arg }]
}),
addNewPost: builder.mutation<Post, NewPost>({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
}),
editPost: builder.mutation<Post, PostUpdate>({
query: post => ({
url: `posts/${post.id}`,
method: 'PATCH',
body: post
}),
invalidatesTags: (result, error, arg) => [{ type: 'Post', id: arg.id }]
})
})
})
It's possible for the result argument in these callbacks to be undefined if the response has no data or there's an error, so we have to handle that safely. For getPosts we can do that by using a default argument array value to map over, and for getPost we're already returning a single-item array based on the argument ID. For editPost, we know the ID of the post from the partial post object that was passed into the trigger function, so we can read it from there.
With those changes in place, let's go back and try editing a post again, with the Network tab open in the browser DevTools.
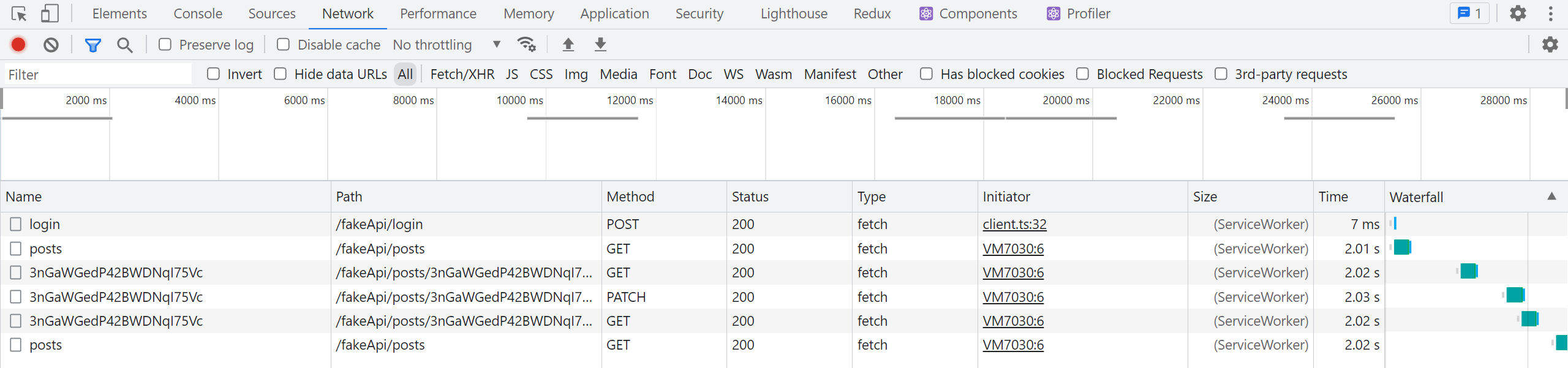
When we save the edited post this time, we should see two requests happen back-to-back:
- The
PATCH /posts/:postIdfrom theeditPostmutation - A
GET /posts/:postIdas thegetPostquery is refetched
Then, if we click back to the main "Posts" tab, we should also see:
- A
GET /postsas thegetPostsquery is refetched
Because we provided the relationships between the endpoints using tags, RTK Query knew that it needed to refetch the individual post and the list of posts when we made that edit and the specific tag with that ID was invalidated - no further changes needed! Meanwhile, as we were editing the post, the cache removal timer for the getPosts data expired, so it was removed from the cache. When we opened the <PostsList> component again, RTK Query saw that it did not have the data in cache and refetched it.
There is one caveat here. By specifying a plain 'Post' tag in getPosts and invalidating it in addNewPost, we actually end up forcing a refetch of all individual posts as well. If we really want to just refetch the list of posts for the getPost endpoint, you can include an additional tag with an arbitrary ID, like {type: 'Post', id: 'LIST'}, and invalidate that tag instead. The RTK Query docs have a table that describes what will happen if certain general/specific tag combinations are invalidated.
RTK Query has many other options for controlling when and how to refetch data, including "conditional fetching", "lazy queries", and "prefetching", and query definitions can be customized in a variety of ways. See the RTK Query usage guide docs for more details on using these features:
Updating Toast Display
When we switched from dispatching thunks for adding posts to using an RTK Query mutation, we accidentally broke the "New post added" toast message behavior, because the addNewPost.fulfilled action is no longer getting dispatched.
Fortunately, this is simple to fix. RTK Query actually uses createAsyncThunk internally, and we've already seen that it dispatches Redux actions as the requests are made. We can update the toast listener to watch for RTKQ's internal actions being dispatched, and show the toast message when that happens.
createApi automatically generates thunks internally for each endpoint. It also automatically generates RTK "matcher" functions, which accept an action object and return true if the action matches some condition. These matchers can be used in any place that needs to check if an action matches a given condition, such as inside startAppListening. They also act as TypeScript type guards, narrowing the TS type of the action object so that you can safely access its fields.
Currently, the toast listener is watching for the single specific action type with actionCreator: addNewPost.fulfilled. We'll update it to watch for the posts being added with matcher: apiSlice.endpoints.addNewPost.matchFulfilled:
import { createEntityAdapter, createSelector, createSlice, EntityState, PayloadAction } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { AppStartListening } from '@/app/listenerMiddleware'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { logout } from '@/features/auth/authSlice'
// omit types, posts slice, and selectors
export const addPostsListeners = (startAppListening: AppStartListening) => {
startAppListening({
matcher: apiSlice.endpoints.addNewPost.matchFulfilled,
effect: async (action, listenerApi) => {
Now the toast should show correctly again when we add a post.
Managing Users Data
We've finished converting our posts data management over to use RTK Query. Next up, we'll convert the list of users.
Since we've already seen how to use the RTK Query hooks for fetching and reading data, for this section we're going to try a different approach. Like the rest of Redux Toolkit, RTK Query's core logic is UI-agnostic and can be used with any UI layer, not just React.
Normally you should use the React hooks that createApi generates, since they do a lot of work for you. But, for sake of illustration, here we're going to work with the user data using just the RTK Query core API so you can see how to use it.
Fetching Users Manually
We're currently defining a fetchUsers async thunk in usersSlice.ts, and dispatching that thunk manually in main.tsx so that the list of users is available as soon as possible. We can do that same process using RTK Query.
We'll start by defining a getUsers query endpoint in apiSlice.ts, similar to our existing endpoints. We'll export the useGetUsersQuery hook just for consistency, but for now we're not going to use it.
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
import type { Post, NewPost, PostUpdate } from '@/features/posts/postsSlice'
import type { User } from '@/features/users/usersSlice'
export type { Post }
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useGetUsersQuery,
useAddNewPostMutation,
useEditPostMutation
} = apiSlice
If we inspect the API slice object, it includes an endpoints field, with one endpoint object inside for each endpoint we've defined.

Each endpoint object contains:
- The same primary query/mutation hook that we exported from the root API slice object, but named as
useQueryoruseMutation - For query endpoints, an additional set of query hooks for scenarios like "lazy queries" or partial subscriptions
- A set of "matcher" utilities to check for the
pending/fulfilled/rejectedactions dispatched by requests for this endpoint - An
initiatethunk that triggers a request for this endpoint - A
selectfunction that creates memoized selectors that can retrieve the cached result data + status entries for this endpoint
If we want to fetch the list of users outside of React, we can dispatch the getUsers.initiate() thunk in our index file:
// omit other imports
import { apiSlice } from './features/api/apiSlice'
async function main() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSlice.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
main()
This dispatch happens automatically inside the query hooks, but we can start it manually if needed by dispatching the initiate thunk.
Note that we didn't provide an argument to initiate(). That's because our getUsers endpoint doesn't need a specific query argument. Conceptually, this is the same as saying "this cache entry has a query argument of undefined". If we did need arguments, we'd pass them to the thunk, like dispatch(apiSlice.endpoints.getPokemon.initiate('pikachu')).
In this case, we're manually dispatching the thunk to start prefetching the data in our app's setup function. In practice, you may want to do the prefetching in React-Router's "data loaders" to start the requests before the components are rendered. (See the RTK repo discussion thread on React-Router loaders for some ideas.)
Manually dispatching an RTKQ request thunk will create a subscription entry, but it's then up to you to unsubscribe from that data later - otherwise the data stays in the cache permanently. In this case, we always need user data, so we can skip unsubscribing.
Selecting Users Data
We currently have selectors like selectAllUsers and selectUserById that are generated by our createEntityAdapter users adapter, and are reading from state.users. If we reload the page, all of our user-related display is broken because the state.users slice has no data. Now that we're fetching data for RTK Query's cache, we should replace those selectors with equivalents that read from the cache instead.
The endpoint.select() function in the API slice endpoints will create a new memoized selector function every time we call it. select() takes a cache key as its argument, and this must be the same cache key that you pass as an argument to either the query hooks or the initiate() thunk. The generated selector uses that cache key to know exactly which cached result it should return from the cache state in the store.
In this case, our getUsers endpoint doesn't need any parameters - we always fetch the entire list of users. So, we can create a cache selector with no argument (which is the same as passing a cache key of undefined).
We can update usersSlice.ts to base its selectors on the RTKQ query cache instead of the actual usersSlice call:
import {
createEntityAdapter,
createSelector,
createSlice
} from '@reduxjs/toolkit'
import { client } from '@/api/client'
import type { RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUserId } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
// omit `fetchSlice` and `usersSlice`
const emptyUsers: User[] = []
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSlice.endpoints.getUsers.select()
export const selectAllUsers = createSelector(
selectUsersResult,
usersResult => usersResult?.data ?? emptyUsers
)
export const selectUserById = createSelector(
selectAllUsers,
(state: RootState, userId: string) => userId,
(users, userId) => users.find(user => user.id === userId)
)
export const selectCurrentUser = (state: RootState) => {
const currentUserId = selectCurrentUserId(state)
if (currentUserId) {
return selectUserById(state, currentUserId)
}
}
/* Temporarily ignore adapter selectors - we'll come back to this later
export const { selectAll: selectAllUsers, selectById: selectUserById } = usersAdapter.getSelectors(
(state: RootState) => state.users,
)
*/
We start by creating a specific selectUsersResult selector instance that knows how to retrieve the right cache entry.
Once we have that initial selectUsersResult selector, we can replace the existing selectAllUsers selector with one that returns the array of users from the cache result. Since there might not be a valid result yet, we fall back to an emptyUsers array. We'll also replace selectUserById with one that finds the right user from that array.
For now we're going to comment out those selectors from the usersAdapter - we're going to make another change later that switches back to using those.
Our components are already importing selectAllUsers, selectUserById, and selectCurrentUser, so this change should just work! Try refreshing the page and clicking through the posts list and single post view. The correct user names should appear in each displayed post, and in the dropdown in the <AddPostForm>.
Note that this is a great example of how using selectors makes the code more maintainable! We already had our components calling these selectors, so they don't care whether the data is coming from the existing usersSlice state, or from an RTK Query cache entry, as long as the selectors return the expected data. We were able to change out the selector implementations and didn't have to update the UI components at all.
Since the usersSlice state is no longer even being used at all, we can go ahead and delete the const usersSlice = createSlice() call and the fetchUsers thunk from this file, and remove users: usersReducer from our store setup. We've still got a couple bits of code that reference postsSlice, so we can't quite remove that yet - we'll get to that shortly.
Splitting and Injecting Endpoints
We said that RTK Query normally has a single "API slice" per application, and so far we've defined all of our endpoints directly in apiSlice.ts. But, it's common for larger applications to "code-split" features into separate bundles, and then "lazy load" them on demand as the feature is used for the first time. . What happens if we want to code-split some of our endpoint definitions, or move them into another file to keep the API slice file from getting too big?
RTK Query supports splitting out endpoint definitions with apiSlice.injectEndpoints(). That way, we can still have a single API slice instance, with a single middleware and cache reducer, but we can move the definition of some endpoints to other files. This enables code-splitting scenarios, as well as co-locating some endpoints alongside feature folders if desired.
To illustrate this process, let's switch the getUsers endpoint to be injected in usersSlice.ts, instead of defined in apiSlice.ts.
We're already importing apiSlice into usersSlice.ts so that we can access the getUsers endpoint, so we can switch to calling apiSlice.injectEndpoints() here instead.
import { apiSlice } from '../api/apiSlice'
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<User[], void>({
query: () => '/users'
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
injectEndpoints() mutates the original API slice object to add the additional endpoint definitions, and then returns the same API reference. Additionally, the return value of injectEndpoints has the additional TS types from the injected endpoints included.
Because of that, we should save this as a new variable with a different name, so that we can use the updated TS types, have everything compile correctly, and remind ourselves which version of the API slice we're using. Here, we'll call it apiSliceWithUsers to differentiate it from the original apiSlice.
At the moment, the only file that references the getUsers endpoint is our entry point file, which is dispatching the initiate thunk. We need to update that to import the extended API slice instead:
import { apiSliceWithUsers } from './features/users/usersSlice'
import { worker } from './api/server'
import './index.css'
// Wrap app rendering so we can wait for the mock API to initialize
async function start() {
// Start our mock API server
await worker.start({ onUnhandledRequest: 'bypass' })
store.dispatch(apiSliceWithUsers.endpoints.getUsers.initiate())
const root = createRoot(document.getElementById('root')!)
root.render(
<React.StrictMode>
<Provider store={store}>
<App />
</Provider>
</React.StrictMode>
)
}
Alternately, you could just export the specific endpoints themselves from the slice file, the same way we've done with action creators in slices.
Manipulating Response Data
So far, all of our query endpoints have simply stored the response data from the server exactly as it was received in the body. getPosts and getUsers both expect the server to return an array, and getPost expects the individual Post object as the body.
It's common for clients to need to extract pieces of data from the server response, or to transform the data in some way before caching it. For example, what if the /getPost request returns a body like {post: {id}}, with the data nested?
There's a couple ways that we could handle this conceptually. One option would be to extract the responseData.post field and store that in the cache, instead of the entire body. Another would be to store the entire response data in the cache, but have our components specify just a specific piece of that cached data that they need.
Transforming Responses
Endpoints can define a transformResponse handler that can extract or modify the data received from the server before it's cached. For example, if getPost returned {post: {id}}, we could have transformResponse: (responseData) => responseData.post, and it would cache just the actual Post object instead of the entire body of the response.
In Part 6: Performance and Normalization, we discussed reasons why it's useful to store data in a normalized structure. In particular, it lets us look up and update items based on an ID, rather than having to loop over an array to find the right item.
Our selectUserById selector currently has to loop over the cached array of users to find the right User object. If we were to transform the response data to be stored using a normalized approach, we could simplify that to directly find the user by ID.
We were previously using createEntityAdapter in usersSlice to manage normalized users data. We can integrate createEntityAdapter into our extendedApiSlice, and actually use createEntityAdapter to transform the data before it's cached. We'll uncomment the usersAdapter lines we originally had, and use its update functions and selectors again.
import {
createSelector,
createEntityAdapter,
EntityState
} from '@reduxjs/toolkit'
import type { RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
import { selectCurrentUsername } from '@/features/auth/authSlice'
export interface User {
id: string
name: string
}
const usersAdapter = createEntityAdapter<User>()
const initialState = usersAdapter.getInitialState()
// This is the _same_ reference as `apiSlice`, but this has
// the TS types updated to include the injected endpoints
export const apiSliceWithUsers = apiSlice.injectEndpoints({
endpoints: builder => ({
getUsers: builder.query<EntityState<User, string>, void>({
query: () => '/users',
transformResponse(res: User[]) {
// Create a normalized state object containing all the user items
return usersAdapter.setAll(initialState, res)
}
})
})
})
export const { useGetUsersQuery } = apiSliceWithUsers
// Calling `someEndpoint.select(someArg)` generates a new selector that will return
// the query result object for a query with those parameters.
// To generate a selector for a specific query argument, call `select(theQueryArg)`.
// In this case, the users query has no params, so we don't pass anything to select()
export const selectUsersResult = apiSliceWithUsers.endpoints.getUsers.select()
const selectUsersData = createSelector(
selectUsersResult,
// Fall back to the empty entity state if no response yet.
result => result.data ?? initialState
)
export const selectCurrentUser = (state: RootState) => {
const currentUsername = selectCurrentUsername(state)
if (currentUsername) {
return selectUserById(state, currentUsername)
}
}
export const { selectAll: selectAllUsers, selectById: selectUserById } =
usersAdapter.getSelectors(selectUsersData)
We've added a transformResponse option to the getUsers endpoint. It receives the entire response data body as its argument (in this case, a User[] array), and should return the actual data to be cached. By calling usersAdapter.setAll(initialState, responseData), it will return the standard {ids: [], entities: {}} normalized data structure containing all of the received items. We need to tell TS that we're now returning that EntityState<User, string> data as the actual contents of the cache entry's data field.
The adapter.getSelectors() function needs to be given an "input selector" so it knows where to find that normalized data. In this case, the data is nested down inside the RTK Query cache reducer, so we select the right field out of the cache state. To make things consistent, we can write a selectUsersData selector that falls back to the initial empty normalized state if we haven't yet fetched the data.
Normalized vs Document Caches
It's worth stepping back for a minute to discuss what we just did and why it matters.
You may have heard the term "normalized cache" in relation to other data fetching libraries like Apollo. It's important to understand that RTK Query uses a "document cache" approach, not a "normalized cache".
A fully normalized cache tries to deduplicate similar items across all queries, based on item type and ID. As an example, say that we have an API slice with getTodos and getTodo endpoints, and our components make the following queries:
getTodos()getTodos({filter: 'odd'})getTodo({id: 1})
Each of these query results would include a Todo object that looks like {id: 1}.
In a fully normalized deduplicating cache, only a single copy of this Todo object would be stored. However, RTK Query saves each query result independently in the cache. So, this would result in three separate copies of this Todo being cached in the Redux store. However, if all the endpoints are consistently providing the same tags (such as {type: 'Todo', id: 1}), then invalidating that tag will force all the matching endpoints to refetch their data for consistency.
RTK Query deliberately does not implement a cache that would deduplicate identical items across multiple requests. There are several reasons for this:
- A fully normalized shared-across-queries cache is a hard problem to solve
- We don't have the time, resources, or interest in trying to solve that right now
- In many cases, simply re-fetching data when it's invalidated works well and is easier to understand
- The main goal of RTKQ is to help solve the general use case of "fetch some data", which is a big pain point for a lot of people
In this case, we just normalized the response data for the getUsers endpoint, in that it's being stored as an {[id]: value} lookup table. However, this is not the same thing as a "normalized cache" - we only transformed how this one response is stored rather than deduplicating results across endpoints or requests.
Selecting Values from Results
The last component that is reading from the old postsSlice is <UserPage>, which filters the list of posts based on the current user. We've already seen that we can get the entire list of posts with useGetPostsQuery() and then transform it in the component, such as sorting inside of a useMemo. The query hooks also give us the ability to select pieces of the cached state by providing a selectFromResult option, and only re-render when the selected pieces change.
The useQuery hooks always take the cache key argument as the first parameter, and if you need to provide hook options, that must always be the second parameter, like useSomeQuery(cacheKey, options). In this case, the getUsers endpoint doesn't have any actual cache key argument. Semantically, this is the same as a cache key of undefined. So, in order to provide options to the hook, we have to call useGetUsersQuery(undefined, options).
We can use selectFromResult to have <UserPage> read just a filtered list of posts from the cache. However, in order for selectFromResult to avoid unnecessary re-renders, we need to ensure that whatever data we extract is memoized correctly. To do this, we should create a new selector instance that the <UsersPage> component can reuse every time it renders, so that the selector memoizes the result based on its inputs.
import { Link, useParams } from 'react-router-dom'
import { createSelector } from '@reduxjs/toolkit'
import type { TypedUseQueryStateResult } from '@reduxjs/toolkit/query/react'
import { useAppSelector } from '@/app/hooks'
import { useGetPostsQuery, Post } from '@/features/api/apiSlice'
import { selectUserById } from './usersSlice'
// Create a TS type that represents "the result value passed
// into the `selectFromResult` function for this hook"
type GetPostSelectFromResultArg = TypedUseQueryStateResult<Post[], any, any>
const selectPostsForUser = createSelector(
(res: GetPostSelectFromResultArg) => res.data,
(res: GetPostSelectFromResultArg, userId: string) => userId,
(data, userId) => data?.filter(post => post.user === userId)
)
export const UserPage = () => {
const { userId } = useParams()
const user = useAppSelector(state => selectUserById(state, userId!))
// Use the same posts query, but extract only part of its data
const { postsForUser } = useGetPostsQuery(undefined, {
selectFromResult: result => ({
// Optional: Include all of the existing result fields like `isFetching`
...result,
// Include a field called `postsForUser` in the result object,
// which will be a filtered list of posts
postsForUser: selectPostsForUser(result, userId!)
})
})
// omit rendering logic
}
There's a key difference with the memoized selector function we've created here. Normally, selectors expect the entire Redux state as their first argument, and extract or derive a value from state. However, in this case we're only dealing with the "result" value that is kept in the cache. The result object has a data field inside with the actual values we need, as well as some of the request metadata fields.
Because this selector is receiving something other than the usual RootState type as its first argument, we need to tell TS what that result value looks like. The RTK Query package exports a TS type called TypedUseQueryStateResult that represents "the type of the useQuery hook return object". We can use that to declare that we expect the result to include a Post[] array, and then define our selector using that type.
As of RTK 2.x and Reselect 5.x, memoized selectors have an infinite cache size, so changing the arguments should still keep earlier memoized results available. If you're using RTK 1.x or Reselect 4.x, note that memoized selectors only have a default cache size of 1. You'll need to create a unique selector instance per component to ensure the selector memoizes consistently when passed different arguments like IDs.
Our selectFromResult callback receives the result object containing the original request metadata and the data from the server, and should return some extracted or derived values. Because query hooks add an additional refetch method to whatever is returned here, selectFromResult should always return an object with the fields inside that you need inside.
Since result is being kept in the Redux store, we can't mutate it - we need to return a new object. The query hook will do a "shallow" comparison on this returned object, and only re-render the component if one of the fields has changed. We can optimize re-renders by only returning the specific fields needed by this component - if we don't need the rest of the metadata flags, we could omit them entirely. If you do need them, you can spread the original result value to include them in the output.
In this case, we'll call the field postsForUser, and we can destructure that new field from the hook result. By calling selectPostsForUser(result, userId) every time, it will memoize the filtered array and only recalculate it if the fetched data or the user ID changes.
Comparing Transformation Approaches
We've now seen three different ways that we can manage transforming responses:
- Keep original response in cache, read full result in component and derive values
- Keep original response in cache, read derived result with
selectFromResult - Transform response before storing in cache
Each of these approaches can be useful in different situations. Here's some suggestions for when you should consider using them:
transformResponse: all consumers of the endpoint want a specific format, such as normalizing the response to enable faster lookups by IDselectFromResult: some consumers of the endpoint only need partial data, such as a filtered list- per-component /
useMemo: when only some specific components need to transform the cached data
Advanced Cache Updates
We've completed updating our posts and users data, so all that's left is working with reactions and notifications. Switching these to use RTK Query will give us a chance to try out some of the advanced techniques available for working with RTK Query's cached data, and allow us to provide a better experience for our users.
Persisting Reactions
Originally, we only tracked reactions on the client side and did not persist them to the server. Let's add a new addReaction mutation and use that to update the corresponding Post on the server every time the user clicks a reaction button.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
invalidatesTags: (result, error, arg) => [
{ type: 'Post', id: arg.postId }
]
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation,
useEditPostMutation,
useAddReactionMutation
} = apiSlice
Similar to our other mutations, we take some parameters and make a request to the server, with some data in the body of the request. Since this example app is small, we'll just give the name of the reaction, and let the server increment the counter for that reaction type on this post.
We already know that we need to refetch this post in order to see any of the data change on the client, so we can invalidate this specific Post entry based on its ID.
With that in place, let's update <ReactionButtons> to use this mutation.
import { useAddReactionMutation } from '@/features/api/apiSlice'
import type { Post, ReactionName } from './postsSlice'
const reactionEmoji: Record<ReactionName, string> = {
thumbsUp: '👍',
tada: '🎉',
heart: '❤️',
rocket: '🚀',
eyes: '👀'
}
interface ReactionButtonsProps {
post: Post
}
export const ReactionButtons = ({ post }: ReactionButtonsProps) => {
const [addReaction] = useAddReactionMutation()
const reactionButtons = Object.entries(reactionEmoji).map(
([stringName, emoji]) => {
// Ensure TS knows this is a _specific_ string type
const reaction = stringName as ReactionName
return (
<button
key={reaction}
type="button"
className="muted-button reaction-button"
onClick={() => {
addReaction({ postId: post.id, reaction })
}}
>
{emoji} {post.reactions[reaction]}
</button>
)
}
)
return <div>{reactionButtons}</div>
}
Let's see this in action! Go to the main <PostsList>, and click one of the reactions to see what happens.
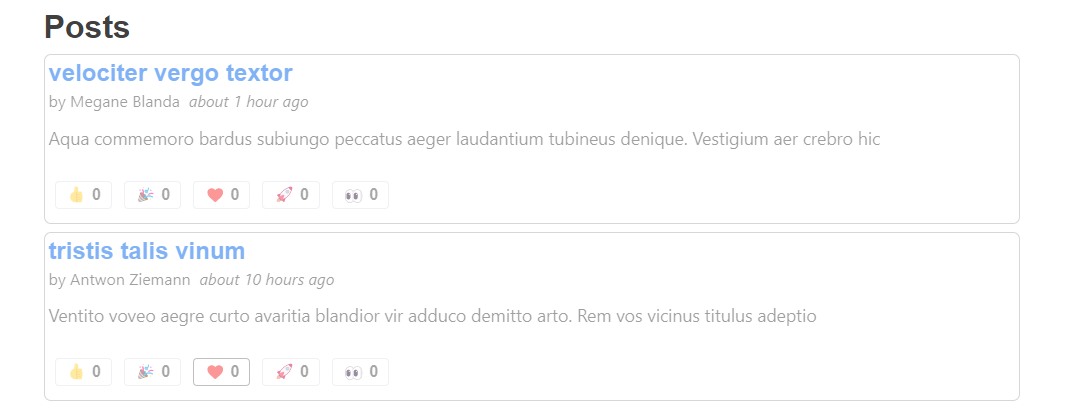
Uh-oh. The entire <PostsList> component was grayed out, because we just refetched the entire list of posts in response to that one post being updated. This is deliberately more visible because our mock API server is set to have a 2-second delay before responding, but even if the response is faster, this still isn't a good user experience.
Optimistic Updates for Reactions
For a small update like adding a reaction, we probably don't need to re-fetch the entire list of posts. Instead, we could try just updating the already-cached data on the client to match what we expect to have happen on the server. Also, if we update the cache immediately, the user gets instant feedback when they click the button instead of having to wait for the response to come back. This approach of updating client state right away is called an "optimistic update", and it's a common pattern in web apps.
RTK Query includes utilities to update the client-side cache directly. This can be combined with RTK Query's "request lifecycle" methods to implement optimistic updates.
Cache Update Utilities
API slices have some additional methods attached, under api.util. This includes thunks for modifying the cache: upsertQueryData to add or replace a cache entry, and updateQueryData to modify a cache entry. Since these are thunks, they can be used anywhere you have access to dispatch.
In particular, the updateQueryData util thunk takes three arguments: the name of the endpoint to update, the same cache key argument used to identify the specific cached entry we want to update, and a callback that updates the cached data. updateQueryData uses Immer, so you can "mutate" the drafted cache data the same way you would in createSlice:
dispatch(
apiSlice.util.updateQueryData(endpointName, queryArg, draft => {
// mutate `draft` here like you would in a reducer
draft.value = 123
})
)
updateQueryData generates an action object with a patch diff of the changes we made. When we dispatch that action, the return value from dispatch is a patchResult object. If we call patchResult.undo(), it automatically dispatches an action that reverses the patch diff changes.
The onQueryStarted Lifecycle
The first lifecycle method we'll look at is onQueryStarted. This option is available for both queries and mutations.
If provided, onQueryStarted will be called every time a new request goes out. This gives us a place to run additional logic in response to the request.
Similar to async thunks and listener effects, the onQueryStarted callback receives the query arg value from the request as its first argument, and a lifecycleApi object as the second argument. lifecycleApi includes the same {dispatch, getState, extra, requestId} values as createAsyncThunk. It also has a couple additional fields that are unique to this lifecycle. The most important one is lifecycleApi.queryFulfilled, a Promise that will resolve when the request returns, and either fulfill or reject based on the request.
Implementing Optimistic Updates
We can use the update utilities inside of the onQueryStarted lifecycle to implement either "optimistic" updates (updating the cache before the request is finished), or "pessimistic" updates (updating the cache after the request is finished).
We can implement the optimistic update by finding the specific Post entry in the getPosts cache, and "mutating" it to increment the reaction counter. We also may have a second copy of the same conceptual individual Post object in the getPost cache for that post ID also, so we need to update that cache entry if it exists as well.
By default, we expect that the request will succeed. In case the request fails, we can await lifecycleApi.queryFulfilled, catch a failure, and undo the patch changes to revert the optimistic update.
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
// omit other endpoints
addReaction: builder.mutation<
Post,
{ postId: string; reaction: ReactionName }
>({
query: ({ postId, reaction }) => ({
url: `posts/${postId}/reactions`,
method: 'POST',
// In a real app, we'd probably need to base this on user ID somehow
// so that a user can't do the same reaction more than once
body: { reaction }
}),
// The `invalidatesTags` line has been removed,
// since we're now doing optimistic updates
async onQueryStarted({ postId, reaction }, lifecycleApi) {
// `updateQueryData` requires the endpoint name and cache key arguments,
// so it knows which piece of cache state to update
const getPostsPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPosts', undefined, draft => {
// The `draft` is Immer-wrapped and can be "mutated" like in createSlice
const post = draft.find(post => post.id === postId)
if (post) {
post.reactions[reaction]++
}
})
)
// We also have another copy of the same data in the `getPost` cache
// entry for this post ID, so we need to update that as well
const getPostPatchResult = lifecycleApi.dispatch(
apiSlice.util.updateQueryData('getPost', postId, draft => {
draft.reactions[reaction]++
})
)
try {
await lifecycleApi.queryFulfilled
} catch {
getPostsPatchResult.undo()
getPostPatchResult.undo()
}
}
})
})
})
For this case, we've also removed the invalidatesTags line we'd just added, since we don't want to refetch the posts when we click a reaction button.
Now, if we click several times on a reaction button quickly, we should see the number increment in the UI each time. If we look at the Network tab, we'll also see each individual request go out to the server as well.
Sometimes mutation requests come back with meaningful data in the server response, such as a final item ID that should replace a temporary client-side ID, or other related data. If we did the const res = await lifecycleApi.queryFulfilled first, we could then use the data from the response after that to apply cache updates as a "pessimistic" update.
Streaming Updates for Notifications
Our final feature is the notifications tab. When we originally built this feature in Part 6, we said that "in a real app, the server would push updates to our client every time something happens". We initially faked that feature by adding a "Refresh Notifications" button, and having it make an HTTP GET request for more notifications entries.
It's common for apps to make an initial request to fetch data from the server, and then open up a Websocket connection to receive additional updates over time. RTK Query's lifecycle methods give us room to implement that kind of "streaming updates" to cached data.
We've already seen the onQueryStarted lifecycle that let us implement optimistic (or pessimistic) updates. Additionally, RTK Query provides an onCacheEntryAdded endpoint lifecycle handler, which is a good place to implement streaming updates. We'll use that capability to implement a more realistic approach to managing notifications.
The onCacheEntryAdded Lifecycle
Like onQueryStarted, the onCacheEntryAdded lifecycle method is available for both queries and mutations.
onCacheEntryAdded will be called any time a new cache entry (endpoint + serialized query arg) is added to the cache. This means it will run less often than onQueryStarted, which runs whenever a request happens.
Similar to onQueryStarted, onCacheEntryAdded receives two parameters. The first is the usual query args value. The second is a slightly different lifecycleApi that has {dispatch, getState, extra, requestId}, as well as an updateCachedData util, an alternate form of api.util.updateCachedData that already knows the right endpoint name and query args to use and does the dispatching for you.
There's also two additional Promises that can be waited on:
cacheDataLoaded: resolves with the first cached value received, and is typically used to wait for an actual value to be in the cache before doing more logiccacheEntryRemoved: resolves when this cache entry is removed (ie, there are no more subscribers and the cache entry has been garbage-collected)
As long as 1+ subscribers for the data are still active, the cache entry is kept alive. When the number of subscribers goes to 0 and the cache lifetime timer expires, the cache entry will be removed, and cacheEntryRemoved will resolve. Typically, the usage pattern is:
await cacheDataLoadedright away- Create a server-side data subscription like a Websocket
- When an update is received, use
updateCachedDatato "mutate" the cached values based on the update await cacheEntryRemovedat the end- Clean up subscriptions afterwards
This makes onCacheEntryAdded a good place to put longer-running logic that should keep going as long as the UI needs this particular piece of data. A good example might be a chat app that needs to fetch initial messages for a chat channel, uses a Websocket subscription to receive additional messages over time, and disconnects the Websocket when the user closes the channel.
Fetching Notifications
We'll need to break this work into a few steps.
First, we'll set up a new endpoint for notifications, and add a replacement for the fetchNotificationsWebsocket thunk that will trigger our mock backend to send back notifications via a websocket instead of as an HTTP request.
We'll inject the getNotifications endpoint in notificationsSlice like we did with getUsers, just to show it's possible.
import { createEntityAdapter, createSlice } from '@reduxjs/toolkit'
import { client } from '@/api/client'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { createAppAsyncThunk } from '@/app/withTypes'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and `fetchNotifications` thunk
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications'
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
getNotifications is a standard query endpoint that will store the ServerNotification objects we received from the server.
Then, in <Navbar>, we can use the new query hook to automatically fetch some notifications. When we do that, we're only getting back ServerNotification objects, not the ClientNotification objects with the additional {read, isNew} fields we've been adding, so we'll have to temporarily disable the check for notification.new:
// omit other imports
import { allNotificationsRead, useGetNotificationsQuery } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
const notificationClassname = classnames('notification', {
// new: notification.isNew,
})
}
// omit rendering
}
If we go into the "Notifications" tab, we should see a few entries show up, but none of them will be colored to indicate they're new. Meanwhile, if we click the "Refresh Notifications" button, we'll see the "unread notifications" counter keep increasing. That's because of two things. The button is still triggering the original fetchNotifications thunk that stores entries in the state.notifications slice. Also, the <NotificationsList> component isn't even re-rendering (it relies on the cached data from the useGetNotificationsQuery hook, not the state.notifications slice), and so the useLayoutEffect isn't running or dispatching allNotificationsRead.
Tracking Client-Side State
The next step is to rethink how we track "read" status for notifications.
Previously, we were taking the ServerNotification objects we fetched from the fetchNotifications thunk, adding the {read, isNew} fields in the reducer, and saving those objects. Now, we're saving the ServerNotification objects in the RTK Query cache.
We could do more manual cache updates. We could use transformResponse to add the additional fields, then do some work to modify the cache itself as the user views the notifications.
Instead, we're going to try a different form of what we were already doing: keeping track of the read status inside of the notificationsSlice.
Conceptually, what we really want to do is track the {read, isNew} status of each notification item. We could do that in the slice and keep a corresponding "metadata" entry for each notification we've received, if we had a way to know when the query hook has fetched notifications and had access to the notification IDs.
Fortunately, we can do that! Because RTK Query is built out of standard Redux Toolkit pieces like createAsyncThunk, it's dispatching a fulfilled action with the results each time a request finishes. We just need a way to listen to that in the notificationsSlice, and we know that createSlice.extraReducers is where we'd need to handle that action.
But what are we listening for? Because this is an RTKQ endpoint, we don't have access to the asyncThunk.fulfilled/pending action creators, so we can't just pass those to builder.addCase().
RTK Query endpoints expose a matchFulfilled matcher function, which we can use inside of extraReducers to listen to the fulfilled actions for that endpoint. (Note that we need to change from builder.addCase() to builder.addMatcher()).
So, we're going to change ClientNotification to be a new NotificationMetadata type, listen for the getNotifications query actions, and store the "just metadata" objects in the slice instead of the entire notifications.
As part of that, we're going to rename notificationsAdapter to metadataAdapter, and replace all mentions of notification variables with metadata for clarity. This may look like a lot of changes, but it's mostly just renaming variables.
We'll also export the entity adapter selectEntities selector as selectMetadataEntities. We're going to need to look up these metadata objects by ID in the UI, and it will be easier to do that if we have the lookup table available in the component.
// omit imports and thunks
// Replaces `ClientNotification`, since we just need these fields
export interface NotificationMetadata {
// Add an `id` field, since this is now a standalone object
id: string
read: boolean
isNew: boolean
}
export const fetchNotifications = createAppAsyncThunk(
'notifications/fetchNotifications',
async (_unused, thunkApi) => {
// Deleted timestamp lookups - we're about to remove this thunk anyway
const response = await client.get<ServerNotification[]>(
`/fakeApi/notifications`
)
return response.data
}
)
// Renamed from `notificationsAdapter`, and we don't need sorting
const metadataAdapter = createEntityAdapter<NotificationMetadata>()
const initialState = metadataAdapter.getInitialState()
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: {
allNotificationsRead(state) {
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
metadata.read = true
})
}
},
extraReducers(builder) {
// Listen for the endpoint `matchFulfilled` action with `addMatcher`
builder.addMatcher(
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
(state, action) => {
// Add client-side metadata for tracking new notifications
const notificationsMetadata: NotificationMetadata[] =
action.payload.map(notification => ({
// Give the metadata object the same ID as the notification
id: notification.id,
read: false,
isNew: true
}))
// Rename to `metadata`
Object.values(state.entities).forEach(metadata => {
// Any notifications we've read are no longer new
metadata.isNew = !metadata.read
})
metadataAdapter.upsertMany(state, notificationsMetadata)
}
)
}
})
export const { allNotificationsRead } = notificationsSlice.actions
export default notificationsSlice.reducer
// Rename the selector
export const {
selectAll: selectAllNotificationsMetadata,
selectEntities: selectMetadataEntities
} = metadataAdapter.getSelectors(
(state: RootState) => state.notifications
)
export const selectUnreadNotificationsCount = (state: RootState) => {
const allMetadata = selectAllNotificationsMetadata(state)
const unreadNotifications = allMetadata.filter(metadata => !metadata.read)
return unreadNotifications.length
}
Then we can read that metadata lookup table into <NotificationsList>, and look up the right metadata object for each notification that we're rendering, and re-enable the isNew check to show the right styling:
import { allNotificationsRead, useGetNotificationsQuery, selectMetadataEntities } from './notificationsSlice'
export const NotificationsList = () => {
const dispatch = useAppDispatch()
const { data: notifications = [] } = useGetNotificationsQuery()
const notificationsMetadata = useAppSelector(selectMetadataEntities)
useLayoutEffect(() => {
dispatch(allNotificationsRead())
})
const renderedNotifications = notifications.map((notification) => {
// Get the metadata object matching this notification
const metadata = notificationsMetadata[notification.id]
const notificationClassname = classnames('notification', {
// re-enable the `isNew` check for styling
new: metadata.isNew,
})
// omit rendering
}
}
Now if we look at the "Notifications" tab, the new notifications are styled correctly... but we still don't get any more notifications, nor do these get marked as read.
Pushing Notifications Via Websocket
We've got a couple more steps to do to finish switching over to getting more notifications via server push.
The next step is to switch our "Refresh Notifications" button from dispatching an async thunk to fetch via HTTP request, to forcing the mock backend to send notifications via a websocket.
Our src/api/server.ts file has a mock Websocket server already configured, similar to the mock HTTP server. Since we don't have a real backend (or other users!), we still need to manually tell the mock server when to send new notifications, so we'll continue faking that by having a button we click to force the update. To do this, server.ts exports a function called forceGenerateNotifications, which will force the backend to push out some notification entries via that websocket.
We're going to replace the fetchNotifications async thunk with a fetchNotificationsWebsocket thunk. fetchNotificationsWebsocket is doing the same kind of work as the existing fetchNotifications async thunk. However, in this case we're not making an actual HTTP request, so there's no await call and no payload to return. We're just calling a function that server.ts exported specifically to let us fake server-side push notifications.
Because of that, fetchNotificationsWebsocket doesn't even need to use createAsyncThunk. It's just a normal handwritten thunk, so we can use the AppThunk type to describe the type of the thunk function and have correct types for (dispatch, getState).
In order to implement the "latest timestamp" check, we do need to add selectors that let us read from the notifications cache entry as well. We'll use the same pattern we saw with the users slice.
import {
createEntityAdapter,
createSlice,
createSelector
} from '@reduxjs/toolkit'
import { forceGenerateNotifications } from '@/api/server'
import type { AppThunk, RootState } from '@/app/store'
import { apiSlice } from '@/features/api/apiSlice'
// omit types and API slice setup
export const { useGetNotificationsQuery } = apiSliceWithNotifications
export const fetchNotificationsWebsocket =
(): AppThunk => (dispatch, getState) => {
const allNotifications = selectNotificationsData(getState())
const [latestNotification] = allNotifications
const latestTimestamp = latestNotification?.date ?? ''
// Hardcode a call to the mock server to simulate a server push scenario over websockets
forceGenerateNotifications(latestTimestamp)
}
const emptyNotifications: ServerNotification[] = []
export const selectNotificationsResult =
apiSliceWithNotifications.endpoints.getNotifications.select()
const selectNotificationsData = createSelector(
selectNotificationsResult,
notificationsResult => notificationsResult.data ?? emptyNotifications
)
// omit slice and selectors
Then we can swap <Navbar> to dispatch fetchNotificationsWebsocket instead:
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
} from '@/features/notifications/notificationsSlice'
import { selectCurrentUser } from '@/features/users/usersSlice'
import { UserIcon } from './UserIcon'
export const Navbar = () => {
// omit hooks
if (isLoggedIn) {
const onLogoutClicked = () => {
dispatch(logout())
}
const fetchNewNotifications = () => {
dispatch(fetchNotificationsWebsocket())
}
Almost there! We're fetching initial notifications via RTK Query, tracking read status on the client side, and we've got the infrastructure set up to force new notifications via a websocket. But, if we click "Refresh Notifications" now, it will throw an error - we don't have the websocket handling implemented yet!
So, let's implement the actual streaming updates logic.
Implementing Streaming Updates
For this app, conceptually we want to check for notifications as soon as the user logs in, and immediately start listening for all future incoming notifications updates. If the user logs out, we should stop listening.
We know that the <Navbar> is only rendered after the user logs in, and it stays rendered the whole time. So, that would be a good place to keep the cache subscription alive. We can do that by rendering the useGetNotificationsQuery() hook in that component.
// omit other imports
import {
fetchNotificationsWebsocket,
selectUnreadNotificationsCount,
useGetNotificationsQuery
} from '@/features/notifications/notificationsSlice'
export const Navbar = () => {
const dispatch = useAppDispatch()
const user = useAppSelector(selectCurrentUser)
// Trigger initial fetch of notifications and keep the websocket open to receive updates
useGetNotificationsQuery()
// omit rest of the component
}
The last step is to actually add the onCacheEntryAdded lifecycle handler to our getNotifications endpoint, and add the logic for working with the websocket.
In this case, we're going to create a new websocket, subscribe to incoming messages from the socket, read the notifications from those messages, and update the RTKQ cache entry with the additional data. This is similar conceptually to what we did with the optimistic updates in onQueryStarted.
There's one other issue we'll run into here. If we're receiving incoming notifications via websocket, there isn't an explicit "request succeeded" action being dispatched, yet we still need to create new notification metadata entries for all of the incoming notifications.
We'll address this by creating a specific new Redux action type that will be used just to signal that "we've received more notifications", and dispatch that from within the websocket handler. Then we can update the notificationsSlice to listen for both the endpoint action and this other action using the isAnyOf matcher utility, and do the same metadata logic in both cases.
import {
createEntityAdapter,
createSlice,
createSelector,
createAction,
isAnyOf
} from '@reduxjs/toolkit'
// omit imports and other code
const notificationsReceived = createAction<ServerNotification[]>('notifications/notificationsReceived')
export const apiSliceWithNotifications = apiSlice.injectEndpoints({
endpoints: builder => ({
getNotifications: builder.query<ServerNotification[], void>({
query: () => '/notifications',
async onCacheEntryAdded(arg, lifecycleApi) {
// create a websocket connection when the cache subscription starts
const ws = new WebSocket('ws://localhost')
try {
// wait for the initial query to resolve before proceeding
await lifecycleApi.cacheDataLoaded
// when data is received from the socket connection to the server,
// update our query result with the received message
const listener = (event: MessageEvent<string>) => {
const message: {
type: 'notifications'
payload: ServerNotification[]
} = JSON.parse(event.data)
switch (message.type) {
case 'notifications': {
lifecycleApi.updateCachedData(draft => {
// Insert all received notifications from the websocket
// into the existing RTKQ cache array
draft.push(...message.payload)
draft.sort((a, b) => b.date.localeCompare(a.date))
})
// Dispatch an additional action so we can track "read" state
lifecycleApi.dispatch(notificationsReceived(message.payload))
break
}
default:
break
}
}
ws.addEventListener('message', listener)
} catch {
// no-op in case `cacheEntryRemoved` resolves before `cacheDataLoaded`,
// in which case `cacheDataLoaded` will throw
}
// cacheEntryRemoved will resolve when the cache subscription is no longer active
await lifecycleApi.cacheEntryRemoved
// perform cleanup steps once the `cacheEntryRemoved` promise resolves
ws.close()
}
})
})
})
export const { useGetNotificationsQuery } = apiSliceWithNotifications
const matchNotificationsReceived = isAnyOf(
notificationsReceived,
apiSliceWithNotifications.endpoints.getNotifications.matchFulfilled,
)
// omit other code
const notificationsSlice = createSlice({
name: 'notifications',
initialState,
reducers: { /* omit reducers */ },
extraReducers(builder) {
builder.addMatcher(matchNotificationsReceived, (state, action) => {
// omit logic
}
},
})
When the cache entry is added, we create a new WebSocket instance that will connect to the mock server backend.
We wait for the lifecycleApi.cacheDataLoaded Promise to resolve, at which point we know that the request has completed and we have actual data available.
We need to subscribe to incoming messages from the websocket. Our callback will receive a websocket MessageEvent, and we know that event.data will be a string containing the JSON-serialized notifications data from the backend.
When we receive that message, we parse the contents, and confirm that the parsed object matches the message type that we're looking for. If so, we call lifecycleApi.updateCachedData(), add all the new notifications to the existing cache entry, and re-sort it to make sure they're in the correct order.
Finally, we can also wait for the lifecycleApi.cacheEntryRemoved promise to know when we need to close the websocket and clean up.
Note that it's not required that we create the websocket here in the lifecycle method. Depending on the app structure, you might have created it earlier in the app setup process, and it might be living in another module file or in its own Redux middleware. What actually matters here is that we're using the onCacheEntryAdded lifecycle to know when to start listening for incoming data, inserting the results into the cache entry, and cleaning up when the cache entry goes away.
And that's it! Now when we click "Refresh Notifications", we should see the unread notifications count increase, and clicking over to the "Notifications" tab should highlight read and unread notifications appropriately.
Cleanup
As a final step, we can do some additional cleanup. The actual createSlice call in postsSlice.ts is no longer being used, so we can delete the slice object and its associated selectors + types, then remove postsReducer from the Redux store. We'll leave the addPostsListeners function and the types there, since that's a reasonable place for that code.
What You've Learned
With that, we've finished converting our application over to use RTK Query! All of the data fetching has been switched over to use RTKQ, and we've improved the user experience by adding optimistic updates and streaming updates.
As we've seen, RTK Query includes some powerful options for controlling how we manage cached data. While you may not need all of these options right away, they provide flexibility and key capabilities to help implement specific application behaviors.
Let's take one last look at the whole application in action:
- Specific cache tags can be used for finer-grained cache invalidation
- Cache tags can be either
'Post'or{type: 'Post', id} - Endpoints can provide or invalidate cache tags based on results and arg cache keys
- Cache tags can be either
- RTK Query's APIs are UI-agnostic and can be used outside of React
- Endpoint objects include functions for initiating requests, generating result selectors, and matching request action objects
- Responses can be transformed in different ways as needed
- Endpoints can define a
transformResponsecallback to modify the data before caching - Hooks can be given a
selectFromResultoption to extract/transform data - Components can read an entire value and transform with
useMemo
- Endpoints can define a
- RTK Query has advanced options for manipulating cached data for better user experience
- The
onQueryStartedlifecycle can be used for optimistic updates by updating cache immediately before a request returns - The
onCacheEntryAddedlifecycle can be used for streaming updates by updating cache over time based on server push connections - RTKQ endpoints have a
matchFulfilledmatcher that can be used inside to listen for RTKQ endpoint actions and run additional logic, like updating a slice's state
- The
What's Next?
Congratulations, you've completed the Redux Essentials tutorial! You should now have a solid understanding of what Redux Toolkit and React-Redux are, how to write and organize Redux logic, Redux data flow and usage with React, and how to use APIs like configureStore and createSlice. You should also know how RTK Query can simplify the process of fetching and using cached data.
For more details on using RTK Query, see the RTK Query usage guide docs and API reference.
The concepts we've covered in this tutorial so far should be enough to get you started building your own applications using React and Redux. Now's a great time to try working on a project yourself to solidify these concepts and see how they work in practice. If you're not sure what kind of a project to build, see this list of app project ideas for some inspiration.
The Redux Essentials tutorial is focused on "how to use Redux correctly", rather than "how it works" or "why it works this way". In particular, Redux Toolkit is a higher-level set of abstractions and utilities, and it's helpful to understand what the abstractions in RTK are actually doing for you. Reading through the "Redux Fundamentals" tutorial will help you understand how to write Redux code "by hand", and why we recommend Redux Toolkit as the default way to write Redux logic.
The Using Redux section has information on a number of important concepts, like how to structure your reducers, and our Style Guide page has important information on our recommended patterns and best practices.
If you'd like to know more about why Redux exists, what problems it tries to solve, and how it's meant to be used, see Redux maintainer Mark Erikson's posts on The Tao of Redux, Part 1: Implementation and Intent and The Tao of Redux, Part 2: Practice and Philosophy.
If you're looking for help with Redux questions, come join the #redux channel in the Reactiflux server on Discord.
Thanks for reading through this tutorial, and we hope you enjoy building applications with Redux!